Let’s start by talking about the traditional way people scale applications.
You have a startup, you have a new idea, so you throw something out there fast, maybe it’s a Rails app with a mongoDB backend if you’re unlucky, or something like that
Now thing are going pretty good, maybe you have time and you re-write into something sensible at this point as you business grows and you get more devs, so now you’re on a nice react website with dotnet or node backend or something. But your going slow due to too many users, so you start to scale, first thing people do is this, load balancer in front, horizontally scale the web layer

Now that doesn’t seem too bad, with a few cache optimizations you’re probably handling a few thousands users simultaneous and felling happy. But you keep growing and now you need to handle tens of thousands, so the architecture starts to break out vertically.
So lets imagine something like the below, and if we’ve been good little vegemites we have a good separation of domains, so are able to scale the db by separating the domains out into microservices on the backend with their own independent data.
Our web site then ends up looking a bit like a BFF (Backend For Frontend), and we scale nicely and are able to start to scale up to tens or into the hundreds of thousands of users. And if you are using AWS especially you are going have these lovely Elastically Scaling Load balancers everywhere.

Now when everything is working its fine, but let’s look at a failure scenario.
One of the API B server’s goes offline, like dead, total hardware failure. What happens in the seconds that follow.

To start, let’s look at load balancer redundancy methods, LBs use a health-check endpoint, an aggressive setting would be to ping it every 2 seconds, then after 2 consecutive failures failures take the node offline.
Let’s also take the example we are getting 1,000 requests per second from our BFF.
Second 1
Lose 333 Requests
Second 2
Lose 333 Requests
Health check fails first time
Second 3
Lose 333 Requests
Second 4
Lose 333 Requests
Health check fails second time and LB stops sending traffic to node
So in this scenario we’ve lost about 1300 requests, but we’ve recovered.
Now you say, but how about we get more aggressive with the health check? This only goes so far.
At scale, the more common outage are not ones where things going totally offline (although this does happen), they are ones where things go “slow”.
Now imagine we have aggressive LB health checks (the ones above are already very aggressive so you cant get much more usually), and things are going “slow” to the point health checks are randomly timing out, you’ll start to see nodes pop on and offline randomly, your load will get unevenly distributed to the point usually where you may even have periods of no nodes online, 503s FTW!. I’ve witnessed this first hand, it happens with agressive health checks 🙂
Next is, what happens if your load balancer goes offline? While load balancers are generally very reliable, things like config updates and firmware updates are times when they most commonly fail, but even then, they still can succumb to hardware failure.
If you are running in e-commerce like I have been for the last 15 odd years then traffic is money, every bit of traffic you lose can potentially be costing you money.
Also when you start to get into very large scale, the natural entropy on hardware means hardware failure becomes more common. For example, if you have say 5,000 physical server in your cloud, how often will you have a failure that takes applications offline.
And it doesn’t matter if you are running AWS cloud, kubernetes, etc hardware failure still takes things offline, your VMs and containers may restart with little to no data loss, but they still go offline for periods.
How do we deal with this then? How about Client-side Weighted round-robin?
WTF is that? I hear you say. Good Question!
It’s were we move the load balancing mechanism to the client that is calling the backend. There is several advantages to doing this.
This is usually coupled with a service discovery system, we use consul these days, but there is lots out there.
The basic concept is that the client get a list of all available nodes for a given service. They will the maintain they own in memory list of them and round robin through them similar to a load balancer.

This removes infrastructure (i.e. cost and complexity)
The big differences comes though that the client can retry the request on a different node. You can implement retries when you have a load balancer in front of you, but you are in effect rolling the dice, having the knowledge of the endpoint on the client side means that the retries can be targeted at a different server to the one that errored, or timed out.
What’s the Weighting part though?
Each client maintains its own list of failures, so for example if a client got a 500 or timeout from a node, it would weight him down and start to call him less, this cause a node specific back off, which is extremely important in the more common outage at scale of its “slow”, so if a particular node has been smashed a bit too much by something and is overloaded the clients will slow back off that guy.
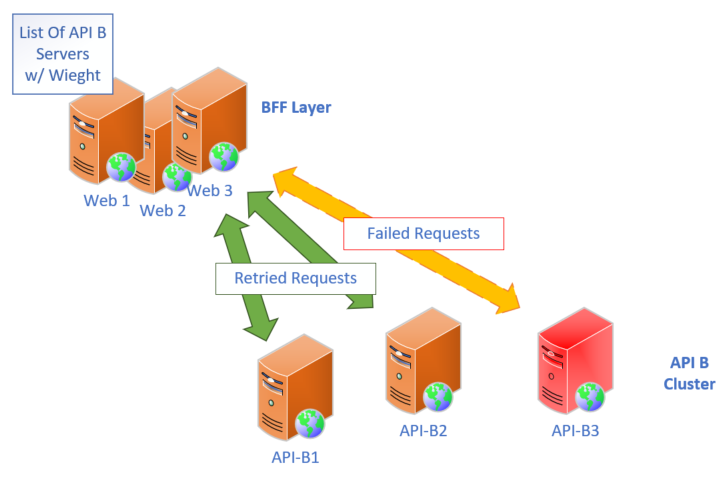
Let’s look at the same scenario as before with API B and a node going offline. We usually set our timeouts to 500ms to 1 second for our API requests, so let’s say 1 second, as the requests start to fail they will retry on the next node in the list, and weight down the offline server in the local clients list of servers/weighting, so here’s what it looks like:
Second 1
220 Requests take 1 second longer
Second 2
60 Requests take 1 second longer
Second 3
3 Requests take 1 second longer
Second 4
3 Requests take 1 second longer
Second 5
…
The Round robin weighting kicks in at the first failure, as we only have 3 web servers in this scenario and they are high volume the back-off isn’t decremented in periods of seconds its in number of requests.
Eventually we get to the point that we are trying the API once every few seconds with a request from each web server until he comes back online, or until the service discover system kicks in and tells us he’s dead (which usually takes under 10 seconds)
But the end result is 0 lost requests.
And this is why I don’t use load balancers any more 🙂

As a disadvantage same load balancing algorithm has to be implemented for every programming language which is used in a company
LikeLike
Yep, so how about we open source it to make it easier for everyone? 🙂
LikeLike