We have been suing Telerik Platform for a while now, while their platform is great, going from TFVC to Build to Platform for deploy always involved someone building for their local visual studio, which of course carries the risks of:
- Manually changing settings from local to dev/test/live and things getting missed
- Unchecked-in code going up
- Manual Labor
So since they have a CLI we decided to try to automate this process, its a bit wired what we came up with because we build at deployment time, but it works.
I setup a git repo for this one with an example solution using the friends app (https://github.com/HostedSolutions/platform-friends-hybrid)
Summary of what we are going to setup with this process
- Package the project into a nuget package on the TeamCity Server and stick it into a nuget server
- Pick up the nuget package with an Octopus Server and store variables for dev/test/prod in octopus
- Deploy to Telerik Platform from the octopus Tentacle
- Based on the octopus environment choose (dev/test/etc) use different variables, and make it available to different group
THE PROJECT
First of all, the project itself. So the Build server in this instance isn’t going to build anything, its just going to package it. so we simply need to add a nuspec file to the project in Visual Studio, example below
<?xml version="1.0" encoding="utf-8" ?> <package xmlns="http://schemas.microsoft.com/packaging/2011/08/nuspec.xsd"> <metadata> <id>platform-friends-hybrid</id> <version>0.0.0</version> <title>platform-friends-hybrid deployment package</title> <authors>Hosted Solutions Pty Ltd</authors> <owners>Hosted Solutions Pty Ltd</owners> <requireLicenseAcceptance>false</requireLicenseAcceptance> <description>platform-friends-hybrid deployment package</description> <summary>platform-friends-hybrid deployment package</summary> <releaseNotes /> <copyright>Copyright © Hosted Solutions Pty Ltd 2015</copyright> <language>en-US</language> </metadata> <files> <file src="\**\*.*" /> <file src=".abproject" /> <file src=".debug.abproject" /> <file src=".release.abproject" /> </files> </package>
Now in this example you will note the files beginning with a “.” i had to add individually. this is because they aren’t picked up by “*.*”
You also need to manually add the packages.config for nuget with a reference to octopack. This will package up the files for you into the nuget format octopus needs.
This Commit in github has the full details (https://github.com/HostedSolutions/platform-friends-hybrid/commit/467c2f06fdb5d123021250902cf0035bf5806790)
Finally we need to change the file /scripts/app/settings.js, so that we can token replace the variables, the need to be in a format of #{VaribleName] for octopus, below is an exmaple
var appSettings = {
everlive: {
apiKey: '#{EVERLIVE_API_KEY}', // Put your Backend Services API key here
scheme: 'http'
},
THE BUILD
To get this to build on your build server you will need to download and install the Visual Studio Extension on your build server as well (https://platform.telerik.com/#workspaces and go to “Getting Started” -> “Downloads” -> “App Builder Hybrid”)

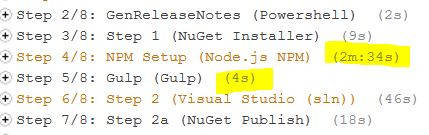
In my build in TeamCity to make this work I’ve got 4 steps

These are very similar to what i outlined in this post (https://beerandserversdontmix.com/2015/09/30/tfs-teamcity-nuget-octopus-somewhere/)
The main difference is I’ve had to add an extra build configuration parameter like this
/p:OctoPackNuGetArguments=-NoDefaultExcludes
This makes Octopack pass an additional parameter to nuget when it does the packaging, without this it refuses to pickup the files beginning with the “.”
Now this will package up our solution to be built on the deployment server, it wont actually do any building.
THE DEPLOY (BUILD)
I’ve got a few projects that are odd like this, where i end up pushing from Octopus to a remote environment to then onward deploy, its not unusual I think, but still not common. So we ended up creating a machine specific in one of our setups for just running scripts, in my smaller setup we just drop a tentacle on our octopus server though.
I’m using an octopus server with a tentacle on it in this example.
First we need to get node js on the box (https://nodejs.org/download/release/latest-v0.12.x/node-v0.12.7-x86.msi)
The tricky bit here is that nodejs with AppManager CLI runs out of the User Profile, so What i have done is set the Tentacle on the box to run a a local User Account (if you are in a domain i recommend an AD account), make sure it a local administrator on the box the tentacle is installed on.

Once this is done login as this user to install and setup nodejs and AppManager CLI with the command line
npm install appbuilder -g

Now that that is ready you need to setup a project in Octopus
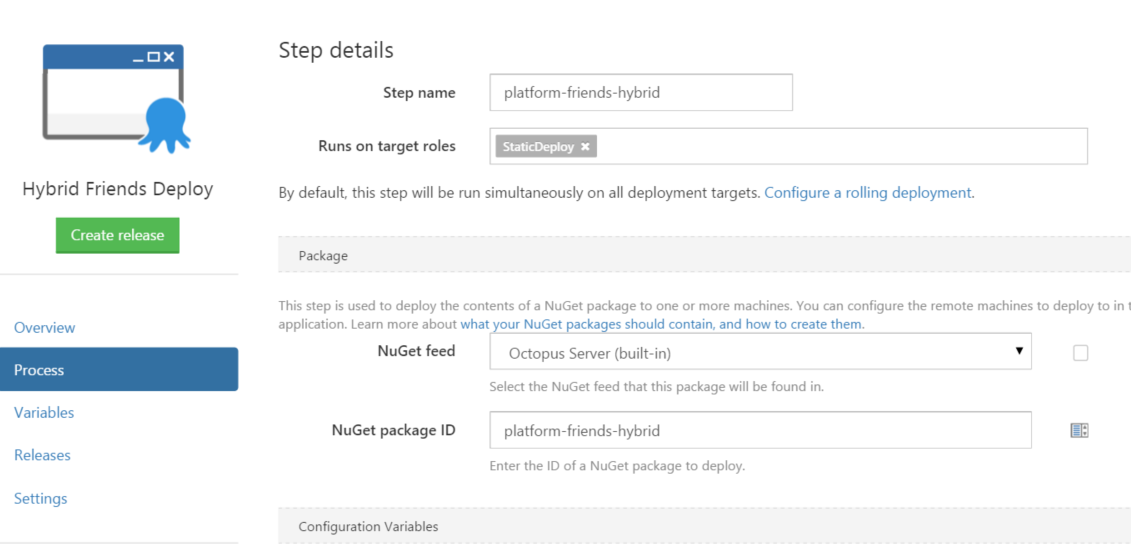
Make sure you select the substitute Variable Step Feature.

And you will need to add you JavaScript Settings file to the list once this is enabled.

The setup the variables in the variable section.

And for each variable you will probably want to set a different scope per environment.

Then add a step template
I’ve put notes for my original powershell script here (https://github.com/HostedSolutions/platform-friends-hybrid/blob/master/NotesOctopusStepTemplate.ps1)
And a full step template for octopus here (https://github.com/HostedSolutions/platform-friends-hybrid/blob/master/OctopusStepTemplate.json)
Now i’ll just walk through a few of the things in the powershell and why we are doing things that way.
# Setup Group Command
$GroupCmd =" --group " + $GroupAccessList.Replace(","," --group ");
$GroupCmd=$GroupCmd.Replace(" "," ").Replace(" "," ")
This code above is for giving the option for various groups to be able to access different deployments. For example, we have Dev and Test, the developers have access to both Dev and Test, but only our testers have access to Test, because we allow the developers to “mess around” with dev, which may cause false positive results in testing.
$currentstepname = $OctopusParameters["Octopus.Step[0].Package.NuGetPackageId"]
We expect the previous step to this one to be the Telerik Nuget Package step, if it is not this will fail.
CMD /C C:\"Program Files (x86)"\nodejs\npm update -g appbuilder; $LASTEXITCODE
We run an update command to make sure that we are on the latest version of AppBuilder, if AppBuilder is not the latest version it will fail
$AppData = $env:APPDATA
AppBuilder runs from the local user profile, so we need to use the AppData folder path
$JSON = (Get-Content "$parentLocation\.abproject" -Raw) | ConvertFrom-Json; # Set values in object $JSON.ProjectName = $ProjectName; $JSON.AppIdentifier = $AppIdentifier; $JSON.DisplayName = $DisplayName; $JSON.BundleVersion = $OctopusReleaseNumber; $JSON | ConvertTo-Json | Set-Content "$parentLocation\.abproject"
We modify values in the .abproject file to set things like the version number and also the app name (we prefix dev with “Dev” and Test with “Test” so using the example above where a developer has both dev and test on their phone, that the developers when they are using the app on their phone know which one is which.
CMD /C $APPDATA\npm\appbuilder dev-telerik-login $TelerikUserName $TelerikPassword IF ($LASTEXITCODE -ne 0) { Write-Error "Error"}
Login to telerik platform
CMD /C $APPDATA\npm\appbuilder appmanager upload android --certificate $AndriodCertID --publish --send-push $GroupCmd;$LASTEXITCODE;IF ($LASTEXITCODE -ne 0) { Write-Error "error"}
Uploads to android
CMD /C $APPDATA\npm\appbuilder appmanager upload ios --certificate $iOSCertID --provision $iOSProvitionID --publish $SendPushCmd $GroupCmd;$LASTEXITCODE;IF ($LASTEXITCODE -ne 0) { Write-Error "error"}
Uploads the iOS version
We normally set the Group Access list to a variable, so that it can be varied per environment.

So we then end up with the steps like so in octopus

Once deployed to Telerik Platform our version number are in sync with Octopus and Team City as well as our Source control labels. And we end up with seperate apps for Dev,Test , etc. and in the event you are accessing services you can token replace the right scoped variable so that the “Test Mobile App” accesses the “Test Web API” and so on.
And there you have it, TFVC -> TeamCity -> Octopus Deploy -> Telerik Platform