I’m going to conflate two topics here as they king of go together to make the title, the first isnt dotnet specific, its a general API principle.
Systems Should Own their Own data
If you can make this work then there’s a lot of advantages. What does this mean in practice though?
It means that tables in your database should only every be read and written by a single system, and there’s a lot of Pros around this. Essentially the below is what I am recommending you AVOID
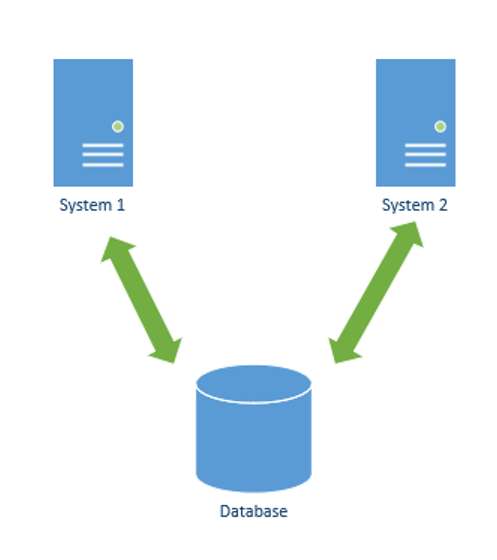
How else to proceed though? there is several options that you may or may not be aware about, I’ll mention a few now but wont go into specifics
Backbend for Front end

Event Sourcing

Data Materialization
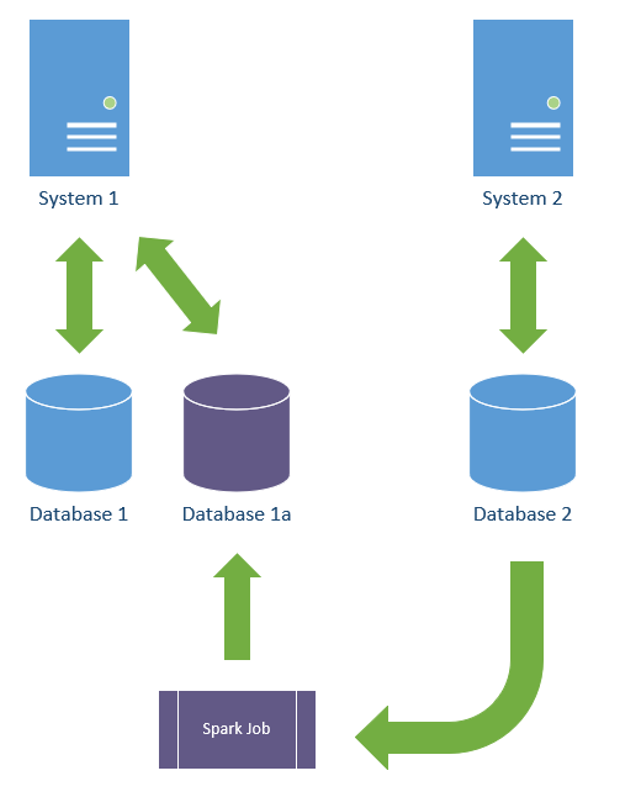
I’ve have other blogs on these. But what you are asking is what’s the benefit right?
If you control data from within a closed systems, its easier to control, a pattern which becomes easy here is known a “write through cache”.
Most of you will be familiar with a “Pull Through Cache”, this is the most common caching pattern, the logic flows like this
- Inbound request for X
- Check cache for key X
- If X found in Cache return
- Else Get X from Database, Update Cache, Return X
So on access we update the cache, and we set an expiry time of Y. And our data is usually stale by Y or less at any given time, unless it hits the DB and then its fresh and slow.
A write through cache is easy to implement when the same system reading is tightly couple with the system writing (or in my recommendation, the same system).
In this scenario the logic works the same, with one difference, when writing we update the cache with the object we are writing, example:
- Inbound update for key X
- Update database for key X
- Update Cache for key X
This way all forces a cache update and your cache is always fresh. Depending on how we implement our cache will vary on how fresh it becomes though. We could work this with local or remote cache.
For small datasets (1s or 10s of Gigabytes in size) I recommend local cache, but if we have a cluster of 3 servers for example how does this work? I generally recommend using a message bus, the example below step 3 sends a message, all APIs in a cluster subscribe to updates on this bus on startup, and use this to know when to re-request updates from DB when update events occur to keep cache fresh. In my experience this sort of pattern leads to 1-4 seconds of cache freshness, depending on your scale (slightly more if geographically distributed)
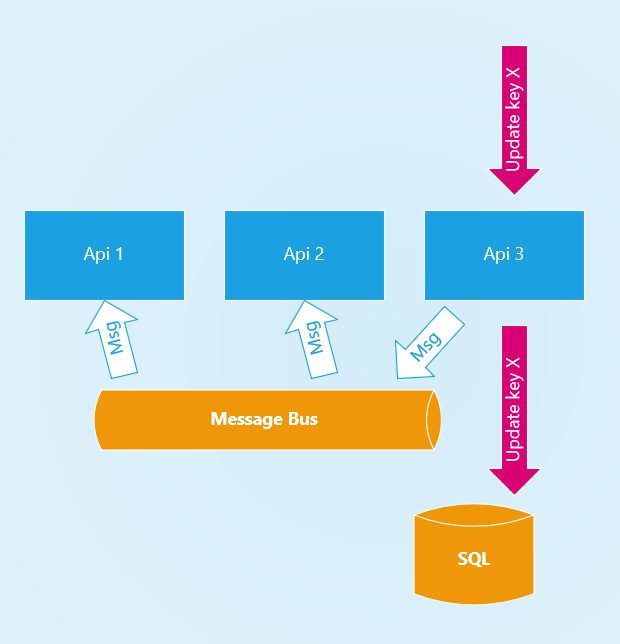
So this isn’t dotnet specific but it makes me lead to my next point. Once you have 10-15Gb of Cache in RAM, how do you handle this? how do you query it? which brings me to the next part.
Working with big-RAM
I’m going to use an example where we used immutable collections to store the data. Update means rebuild the whole collection in this case, we did this because the data updated infrequently, for more frequently updated data DONT do this.
Then used Linq to query into them, collections where 80Mb to 1.2Gb in size in RAM, and some of them had multiple keys to lookup, this was the tricky bit.
The example Data we had was Geographic data (cities, states, points of interest, etc), and we had in the collections multiple languages, so lookups generally had a “Key” plus another “Language Id” to get the correct translation.
So the initial Linq query for this was like
_cityLanguage.FirstOrDefault(x => x.Key.KeyId == cityId && x.Key.LanguageId == languageId).Value;
The results of this are below
| Method | CityNumber | Mean | Error | StdDev |
| LookupCityWithLanguage | 60000 | 929.3 ms | 17.79 ms | 17.48 ms |
You can see the mean response here is almost a second, which isn’t nice user experience.
The next method we tried was to create a dictionary that was keyed on the two fields. To do this on a POCO you need to implement Equals and GetHash code methods so that the dictionary can Hash and compare the keys like below.
class LanguageKey
{
public LanguageKey(int languageId, int keyId)
{
LanguageId = languageId;
KeyId = keyId;
}
public int LanguageId { get; }
public int KeyId { get; }
public override bool Equals(object obj)
{
if(!(obj is LanguageKey)) return false;
var o = (LanguageKey) obj;
return o.KeyId == KeyId && o.LanguageId == LanguageId;
}
public override int GetHashCode()
{
return LanguageId.GetHashCode() ^ KeyId.GetHashCode();
}
public override string ToString()
{
return $"{LanguageId}:{KeyId}";
}
}So the code we end up with is like this for the lookup
_cityLanguage[new LanguageKey(languageId,cityId)];And the results are
| Method | CityNumber | Mean | Error | StdDev |
| LookupCityWithLanguage | 60000 | 332.3 ns | 6.61 ns | 10.86 ns |
Now we can see we’ve gone from milliseconds to nanoseconds a pretty big jump.
The next approach we tried is using a “Lookup” object to store the index below is the code to create the lookup and how to access it.
// in ctor warmup
lookup = _cityLanguage.ToLookup(x => new LanguageKey(x.Key.LanguageId, x.Key.KeyId));
// in method
lookup[new LanguageKey(languageId, cityId)].FirstOrDefault().Value;And the results are similar
| Method | CityNumber | Mean | Error | StdDev |
| LookupCityWithLanguage | 60000 | 386.3 ns | 17.79 ns | 51.89 ns |
We prefer to look at the high percentiles at Agoda though so measure APIs (usually the P90 or P99) below is a peak at how the API is handling the responses.

consistently below 4ms at P90, which is a pretty good experience.
Overall the “Write Through Cache” Approach is a winner for microservices where its common that systems own their own data.
NOTE: this testing was done on an API written in netcore 3.1, I’ll post updates on what it does when we upgrade to 6 🙂
