In my experience in most cases when finding an issue with a dot NET app 90% of issues will have a corresponding exception, this exception might not be the root cause but can lead you to the root cause if you follow it, having clean error logs is essential if you want to get to the root cause fast.
The approach I take with getting to the root cause is pretty straight forward and systematic, but I find a lot that developers don’t seem to grasp troubleshoot concepts like “Process of Elimination” very well, which are common more in the Infrastructure and support side of IT, so I wanted to give a small overview for my Devs.
The steps I usually follow are:
- Check the line of code from the stack trace
- If not enough data, add more and wait for the exception to occur again
- If enough data then fix the problem
This is assuming you cant replicate the exception.
If you take this approach you will eventually get to the root cause and fix an exception, the next step after that is apply this to “every” exception and clean up your logs.
I will use an example of a recent issue I fixed.
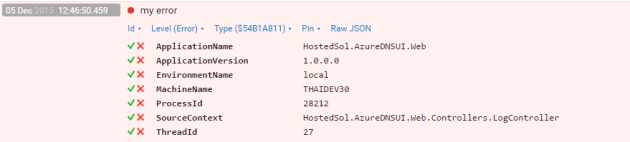
I recently worked on one of our selenium testing projects, which was having some intermittent issues that we couldn’t trouble shoot and there was nothing in the Error Logs, when this happens my initial reaction is to look for code that is swallowing Exceptions, and low and behold I find code like the below that I fixed up.

I fixed about 5 of these in key areas, now I start getting data into my logs, and I get the age old “NullReferenceException”

Looking at the line of code, i can’t tell much, so we are using Serilog, so its easy just to throw some additional objects into the Log.Error method in order to better understand what was going on at run time. In this example the null reference exception was on the line of code that accesses the driverPool object, so I pass this in like below.

Now I wait for the exception to occur again and then check logs.
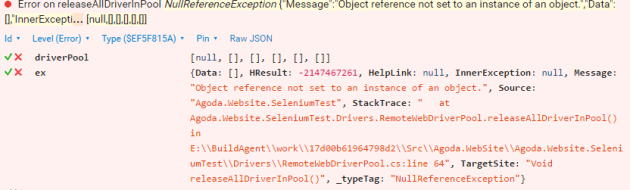
Now i can see the driver pool is a list of null objects. The reason for this will be earlier in the code, but this particular case is filling up the logs so we need to clean it up. So in this situation what i would do is do null check then log a warning message and not attempt the code that is accessing it.
The reason for this is that this method does a “clean up” to dispose the object, but something else has already disposed it, there is not hard set rule here, you need to judge thee on a case by case basis.
After waiting again my error logs are a lot more clean now and I can start to see other exception that I couldn’t see before, below you can visibly see the decrease in volume after I fixed this and a few other errors up as well, after 10:15 when my code was deployed i have 1 exception in the next hour, as opposed to hundreds per minute. My warning logs are a bit more noisy, but that’s ok because I am trying to filter out the noise of the less important errors by using warnings.