We’ve been using a lot of Test Manager Lately and I am really happy with the work flow that is built into TFS with this product.
We have full time testers who don’t have a lot of experience with code, so you can’t give them tools like the CUIT recorder in visual studio and expect them to run with it. But they are the best people to use tools like this because they understand testing more, and also in my experience testers tend to be more thorough than developers.
The other thing I like about the workflow is that its “Documentation First”, so your documentation is inherently linked into the Test platform.
Microsoft Test Manager’s recorder tools is a good cut down version of CUIT that makes things easier for the testers to record manual tests but not get caught up in code.
That being said, it is a pain in the ass to get running, we have a complicated site with a lot of composite controls, so the DOM was a bit ugly, and this made it a painful exercise to get any recorder going (We also tried Teleirk Test Studio and Selenium with similar issues as well, but Telerik Test Studio was probably the best out of them)
The basic workflow in Test Manager Stars with the Test Case work Item, from a test Case you outline your test steps

The important thing here is the use of parameters, you can see in the above example that I am using @URL, @User and @Pass.
In the test case you can input n number of iterations of these, then when creating the test recorder it will play back one iteration per set, this allows testers to go nuts with different sets and edge cases (e.g. 200 Ws for a name, all the special characters in the ASIC set for someone’s last name, Asian character sets, and so on).
Once the documentation is done the test recorder is used (with IE, doesn’t work in other browsers) to save a recorded case. Which can then be played back while someone is watching, which is the first level of automation, i think this is an important first step, because in your development flow if you are working on a new features (requiring a new test case) then you want a set of eyes looking at it first, you don’t want to straight away go to full automation.
It’s important to note though that the test recorder cannot be used to “Assert” values like CUIT, validation of success is done by the Tester looking at the screen and deciding.
When you have past all your newly created test cases and your new features are working, Product Owner and stakeholders are all happy with the UI, this is the point you want to go to full Automation with your UI tests.
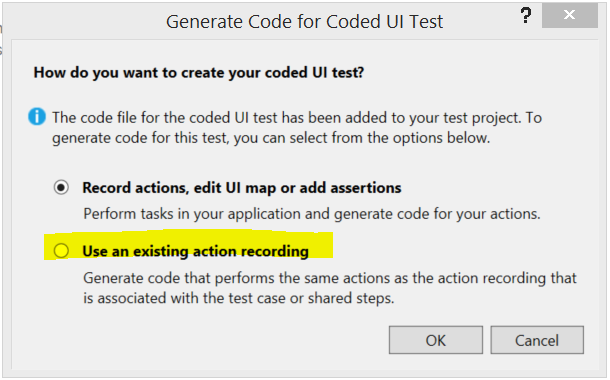
When creating a CodedUI test one of the options is to “Use an existing Recording”

After selecting this you can search through your work items for the test case and Visual Studio will pull out the recording and generate your CodedUI test starting with what your testers have created.

That will go through and generate something like the below code.
[DataSource("Microsoft.VisualStudio.TestTools.DataSource.TestCase", "https://MyTFSServer/tfs/defaultcollection;MyProject", "13934", DataAccessMethod.Sequential)]
[TestMethod]
public void CodedUITestMethod1()
{
// To generate code for this test, select "Generate Code for Coded UI Test" from the shortcut menu and select one of the menu items.
this.UIMap.GoToURLParams.UIboxLoadBalanceWindowUrl = TestContext.DataRow["URL"].ToString();
this.UIMap.GoToURL();
this.UIMap.EnterUserandPassParams.UITxtEmailEditText = TestContext.DataRow["User"].ToString();
this.UIMap.EnterUserandPassParams.UITxtPasswordEditPassword = Playback.EncryptText(TestContext.DataRow["Pass"].ToString());
this.UIMap.EnterUserandPass();
this.UIMap.ClickLoginbutton();
}
The great thing about this is that we can see the attribute for the datasource, it refers to the TFS server and even the work item ID. so this is where the CodedUI test is going to get its data.
So your testers can maintain the data in their Test Plans in TFS and the testing automation will look back into these TFS work items to get their data each time they run.
Now that you are in the CUIT environment you can start to use the CUIT recorder to add Asserts to your tests and validate data. In the above example we might do something like Assert that username text displayed on the page after login is the same as the value we logged in as.
Now we have a working Coded UI test we can add it to a build.
I generally don’t do CodeUI Tests in our standard builds, I don’t know anyone that does, we use n-Tier environment, so in order to run a single app you would need to start up a couple service layers and a database behind it. So i find it better to create a separate solution and builds for the coded UI test and schedule them to run after a full deploy of all layers to test environment overnight.
As in the example above, we put the initial “Open this URL in the Browser” step’s URL as a parameter, so if we want to change the target to another environment, or point it at local host, this is easy, and i defiantly recommend doing this.
So putting it all together we have the below work flow:

Now the thing I like about this is they all feed from the same datasource, which is a Documented Test Plan from your testers, who can then updated a single datasource that’s in a format they not only understand but have control over.
Take the example you are implementing Asian Language support. In the above example you could simple add a new parameter set to the test case that has a Chinese character username in it, which could be done by a tester, then if it wasn’t support the build would start failing.
Lastly I mentioned before IE only, that’s for recording, there is some plugins to allow playback in different browser that I will be checking out soon and make some additional posts about.
This process also works well into your weekly sprint cycles, which I will go into in another post.